
What is VGGNET ??
It is a type of convolutional neural network architecture proposed by K. Simonyan and A. Zisserman from the University of Oxford in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition.
So how it is different from LeNet , AlexNet ??
As we have seen in previous [Alex Net](“https://blurcode.in/blog/what-is-alex-net/") blog, it requires lot of parameters and which very time for training . So here the number of parameters are reduced because of its optimal architecture which ultimately reduces the training time . There are multiple types of VGGNET (vgg16,vgg19 etc) , they can be modified on the category of the problem .
Now let’s understand the architecture of it
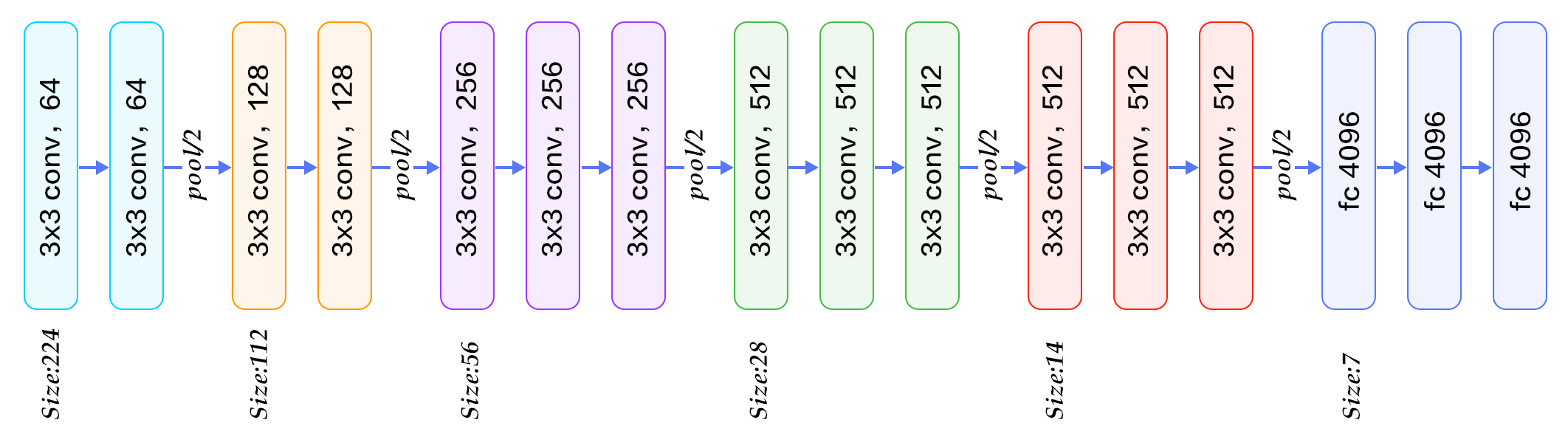
Architecture
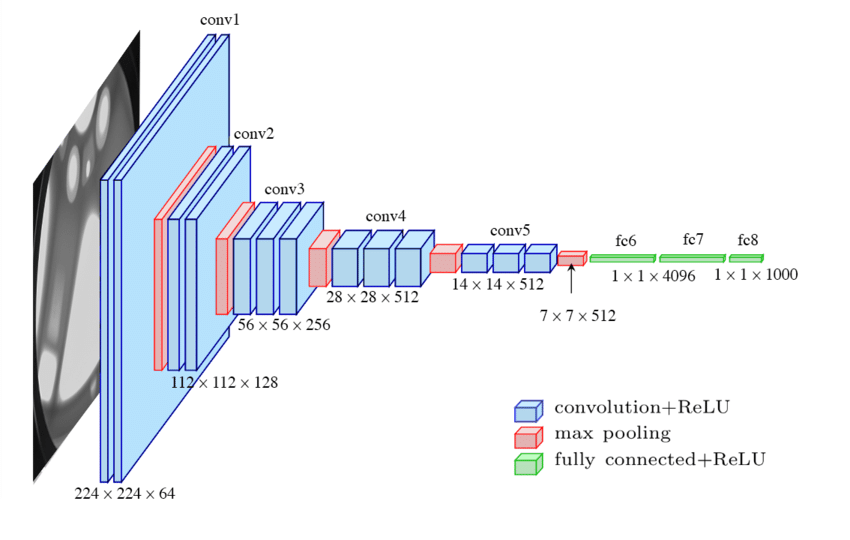
Image reference – www.thedatafrog.com
The core concepts is , all convolutional layers are of size 3*3 and maxpool kernel are of size 2*2, So here instead of making kernel size (11*11,5*5,3*3) in Alex net, here its helping us in reducing the parameters .
After that it has fully connected layers at the end , and in total 16 layers are there .
Trainning
Training follows the same procedure as all previous networks as :-
a) It is carried away by optimizing using mini batch gradient descent(instead of taking all data points , will take the batches of points from training dataset), using it will momentum .
b) Training is regularized by L2 penalty and dropout regularization , which basically means dropping some percentage of neuron from every layer at each epoch or iteration ( try to relate it with Bagging/bootstrap aggregation or random forest ) .
c) Learning rate decay : Decreasing the learning rate by factor of 10 , if accuracy or any other performance metrics stops improving .
d ) Pre-initialization - Initialization of weights are important , because bad initialization can read many problem such as gradient vanishing , stalling of learning rate , gradient exploding etc , random initializing can be done by glorot_uniform , glorot_normal , he_uniform , he_uniform and many more .
Testing
Here the first fully connected (FC) layer is replaced by 7*7 conv. and second and third FC by 1*1 conv.
Here the image directly gets the class score map which is the average of the vectors
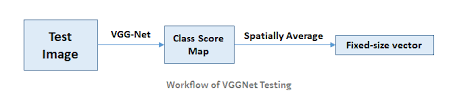
https://stackoverflow.com/questions/60812966/what-is-class-score-map
Implementation
It can implemented with different Framework like tensorflow, Keras , Pytorch , Mxnet , gluon , sonnet etc .
There are already implement modules which are trained on image-net dataset which can be used to train our model by doing some fine tuning depending upon the problem .
But what if dataset is very different from image-net dataset ??
Then we can simply implement it from scratch ,
Its very easy to implement in keras , my personal favorite is Tensorflow with keras .
Same models can be fine-tuned depending on the problem,
Fine tune basically means to use the bottleneck features , and make our own fully connected layers and output layer .
Let us see its implementation in Keras —-
For installation refer this link (https://www.tensorflow.org/install)
Here we are going to use keras on top of tensorflow.
from tensorflow.keras.applications import VGG16
VGG16_model=VGG16(include_top=False,weights="imagenet",input_shape=IMG_SHAPE)
##Weights = pre-trained weight on image-net ## include_top = TOP layer True or False
(see documentation for reference)
Here we have imported the VGGNET module , we can customize according to our problems using transfer Learning (refer https://ai.googleblog.com/2019/12/understanding-transfer-learning-for.html)
Results
VGG16 significantly outperforms the previous generation of models in the ILSVRC-2012 and ILSVRC-2013 competitions. The VGG16 result is also competing for the classification task winner (GoogLeNet with 6.7% error) and substantially outperforms the ILSVRC-2013 winning submission Clarifai, which achieved 11.2% with external training data and 11.7% without it. Concerning the single-net performance, VGG16 architecture achieves the best result (7.0% test error), outperforming a single GoogLeNet by 0.9%.
References
· Original research paper - https://arxiv.org/pdf/1409.1556.pdf
· Code in Keras from scratch – https://github.com/fchollet/deep-learning-(models/blob/master/vgg16.py)
About the author
Atharv Shah , is an undergrad pursuing Btech in computer science , he is fascinated by the artificial intelligence and it’s application used to solve real world problems .

Reviews
If You find it interesting!! we would really like to hear from you.
Ping us at Instagram/@the.blur.code
If you want articles on Any topics dm us on insta.
Thanks for reading!!
Happy Coding


